Overview¶
ELB periodically sends requests to backend servers to check whether they can process requests. If a backend server is detected as unhealthy, the load balancer stops routing requests to it. After the backend server recovers, the load balancer will resume routing requests to it.
If backend servers have to handle large number of requests, frequent health checks may overload the backend servers and cause them to respond slowly. In this case, prolong the health check interval or use TCP or UDP instead of HTTP. If you choose to disable the health check function, requests may be routed to unhealthy servers, and service interruptions may occur.
Prerequisites¶
For TCP and UDP listeners, HTTP 1.1 is used for health checks. For HTTP and HTTPS listeners, HTTP 1.0 is used for health checks.
TCP Health Check¶
For TCP, HTTP, and HTTPS listeners, you can use TCP to initiate three-way handshakes to obtain the statuses of backend servers.
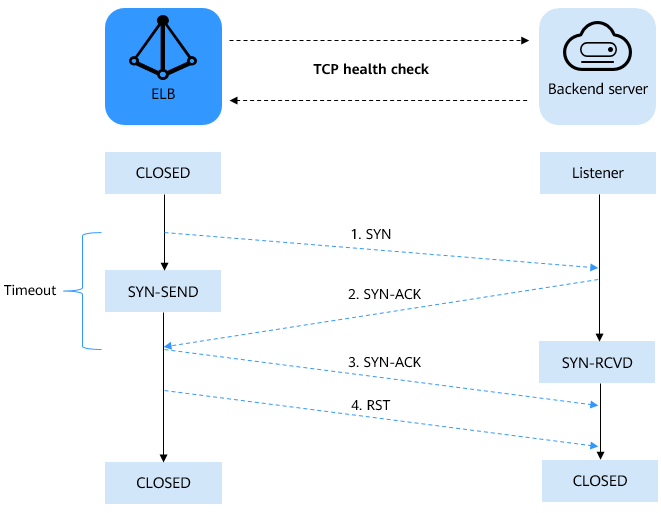
Figure 1 TCP health check¶
The TCP health check process is as follows:
ELB sends an SYN packet to the backend server (in the format of {Private IP address}:{Health check port}).
The backend server returns an SYN-ACK packet.
If ELB does not receive the SYN-ACK packet within the health check timeout duration, the backend server is declared unhealthy. Then, ELB sends an RST packet to the backend server to terminate the TCP connection.
If ELB receives the SYN-ACK packet from the backend server within the health check timeout duration, it sends an ACK packet to the backend server and declares that the backend server is healthy. After that, ELB sends an RST packet to the backend server to terminate the TCP connection.
After a successful TCP three-way handshake, an RST packet will be sent to close the TCP connection. The application on the backend server may consider this packet a connection error and reply with a message, for example, "Connection reset by peer". In this case, take either of the following actions:
Configure an HTTP health check.
Have the backend server ignore the connection error.
UDP Health Check¶
For UDP listeners, ELB sends ICMP and UDP probe packets to backend servers to check their health.
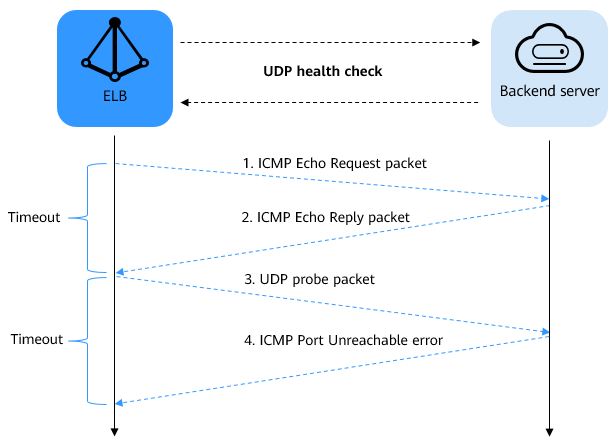
Figure 2 UDP health check¶
The UDP health check process is as follows:
ELB sends an ICMP Echo Request packet to the backend server.
If ELB does not receive the ICMP Echo Reply packet within the health check timeout duration, the backend server is declared unhealthy.
If ELB receives the ICMP Echo Reply packet within the health check timeout duration, it sends a UDP probe packet to the backend server.
If ELB does not receive an ICMP Port Unreachable error within the health check timeout duration, the backend server is declared healthy. If ELB receives an ICMP Port Unreachable error, the backend server is declared unhealthy.
HTTP Health Check¶
You can also configure HTTP health checks for TCP, HTTP, or HTTPS listeners. ELB uses HTTP GET requests to obtain the health statuses of backend servers. For HTTPS listeners, ELB offloads the SSL/TLS encryption and decryption processing from backend servers and uses HTTP to communicate with backend servers by default.

Figure 3 HTTP health check¶
The HTTP health check process is as follows:
ELB sends an HTTP GET request to the backend server (in format of {Private IP address}:{Health check port}/{Health check path}). (You can specify a domain name when configuring a health check.)
The backend server returns an HTTP status code to ELB.
If ELB receives the status code within the health check timeout duration, it compares the status code with the preset status code. If the status codes are the same, the backend server is declared healthy.
If ELB does not receive any response from the backend server within the health check timeout duration, the backend server is declared unhealthy.
Health Check Time Window¶
Health checks greatly improve service availability. However, if health checks are too frequent, service availability will be compromised. To avoid the impact, ELB declares a backend server healthy or unhealthy after several consecutive health checks. There is a time window for the status of a backend server to change between healthy and unhealthy.
The health check time window is determined by the following factors:
Interval: How often health checks are performed.
Timeout: How long the load balancer waits for the response from the backend server.
Maximum Retries: indicates the maximum number of consecutive health checks after which the backend server is declared healthy.
The following is a formula for you to calculate the health check time window:
Time window for a backend server to be considered healthy = Timeout x Maximum retries + Interval x (Maximum retries - 1)
Time window for a backend server to be considered unhealthy = Timeout x 3 + Interval x (3 - 1)
The backend server can be declared unhealthy when three consecutive health checks detect it unhealthy, regardless of the value configured for Maximum Retries.
As shown in Figure 4, if the health check interval is 4s, the health check timeout duration is 2s, and 3 health check retries are performed, the time window for a backend server to be considered unhealthy is calculated as follows: 2 x 3 + 4 x (3 - 1) = 14s.
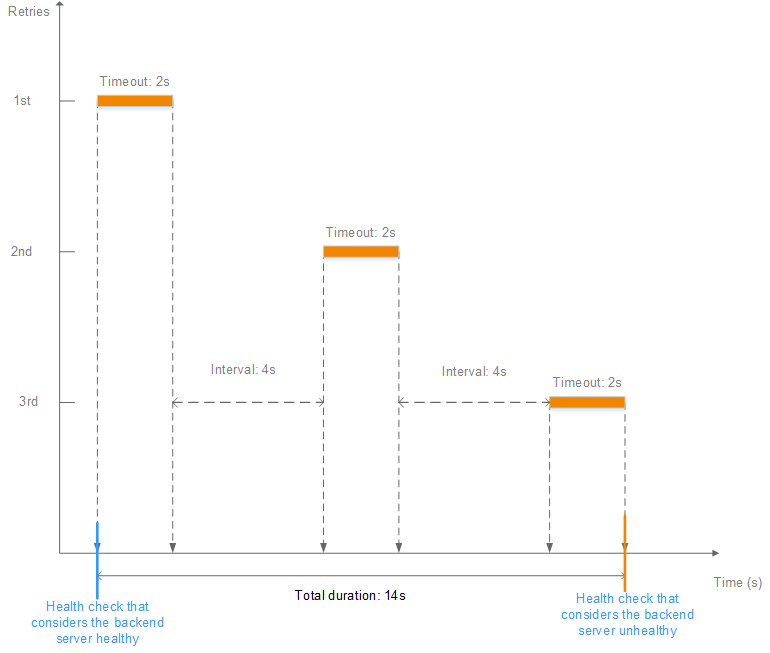
Figure 4 Health check time window¶
Rectifying an Unhealthy Backend Server¶
If a backend server is detected unhealthy, see How Do I Troubleshoot an Unhealthy Backend Server?